Topic Taxonomy
The library-system model of knowledge domains. How topics are defined and validated, the distinction between topic and search terms, hierarchical structure, and why the taxonomy remains stable when search signals change.
Table Of Contents
Summary
The Topic Taxonomy is the structured library of knowledge domains a business genuinely owns. Topics are defined independently of content planning, derived from what the business knows and does, and remain stable when retrieval signals change.
Definition
A topic is a discrete knowledge domain, a subject area narrow enough to be classified separately, broad enough to contain multiple distinct angles of treatment.
The Topic Taxonomy is the structured, hierarchical system of knowledge domains a business has, or is intentionally building, demonstrable authority within.
It functions like the classification system of a specialist library: each topic is a shelf that holds a defined category of knowledge. The shelf exists independently of any books placed on it.
A useful way to understand the taxonomy is that it already exists.
Before any strategy is developed. Before a website is built. Before an SEO practitioner documents it.
The knowledge domains a business operates within are determined by what it does and knows. Not by what a strategist decides to target. Strategy determines how that knowledge is deployed. The taxonomy simply maps what is already there.
Building a Topic Taxonomy is not an act of invention. It is an act of discovery and documentation.
The knowledge exists in the business. The taxonomy makes it legible to buyers, to search systems, and to AI retrieval mechanisms that increasingly mediate how expertise is recognised and cited.
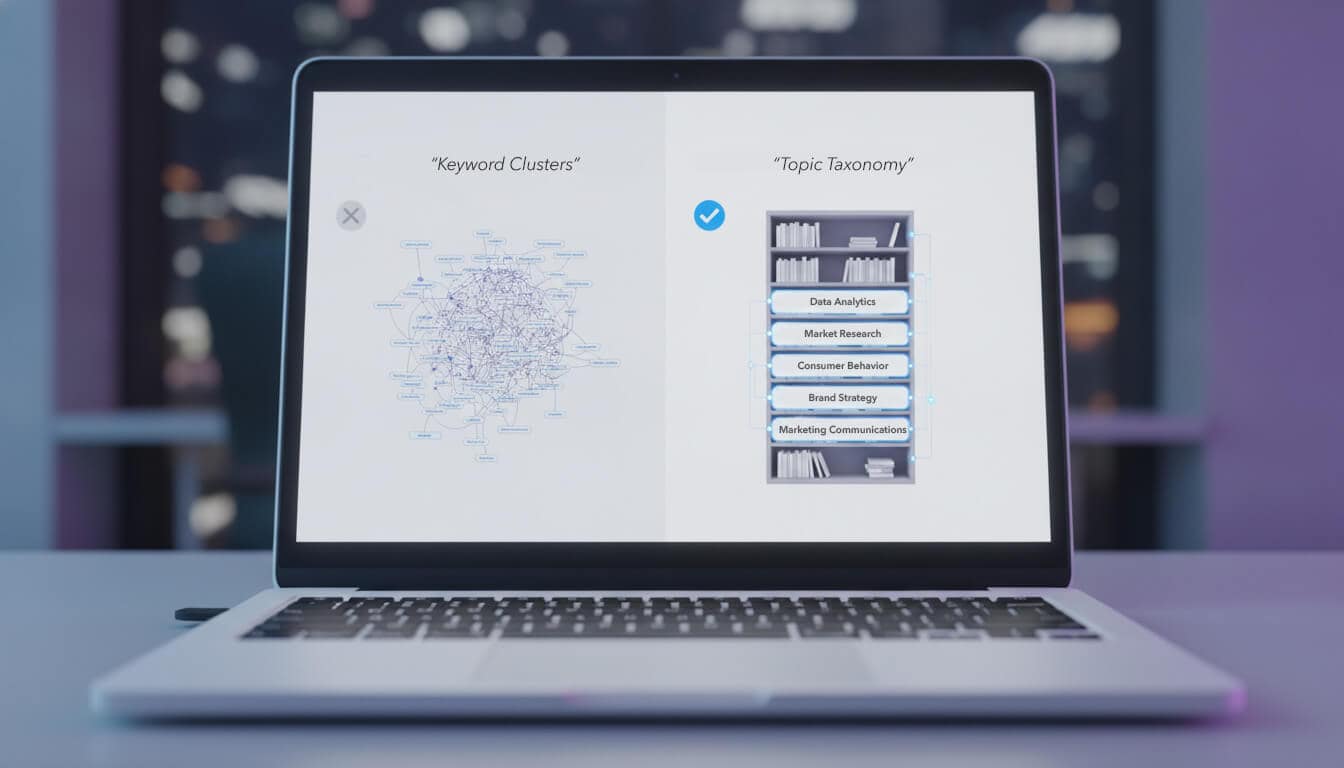
The Library Shelf Test
Before a topic is added to the taxonomy, it is tested against two criteria simultaneously.
Narrow enough to be a distinct knowledge domain. The topic should describe a specific area of expertise that a librarian would shelve separately from adjacent areas.
- “Marketing” fails this test, it is too broad to be a meaningful domain within a business context.
- “Email nurture sequences for service-based businesses” fails it in the other direction, that is an article subject, not a knowledge domain.
Broad enough to contain multiple content angles. A valid topic can be approached from different directions, at different maturity levels, through different cluster lenses, across different audience segments. If a topic can only ever produce one piece of content, it is a subject, not a domain.
The test runs in both directions. A topic that passes both is a valid taxonomy entry. A topic that fails either needs to be elevated to a broader domain or collapsed into an existing one.
The Wikipedia Validation Signal
Wikipedia’s exact-match article test is a useful calibration tool for topic definition.
If a proposed topic corresponds to a discrete Wikipedia article, not a disambiguation page, but a standalone article describing a specific knowledge domain, that is a reasonable signal that the topic is operating at the right level of abstraction.
This works because Wikipedia’s editorial standards require topics to be verifiably distinct knowledge domains with sufficient scope to warrant independent documentation. That standard is close enough to the library shelf test to serve as a quick external reference point.
The Wikipedia signal is a calibration tool, not a hard rule. Some legitimate business knowledge domains are too niched, specific or too recent to have Wikipedia entries. Some Wikipedia articles cover domains too broad for useful taxonomy work. The test narrows the range of plausible topic definitions, it does not determine them.
In SCOS, topic taxonomy entries carry a Wikipedia SameAs URI where one exists. This serves a dual purpose: it confirms the topic is operating as a genuine knowledge domain, and it provides a structured data anchor for schema markup generation.
Hierarchy and Structure
Topic taxonomies are inherently hierarchical but often start flat.
The appropriate structure at any given stage is shaped by strategic maturity, content volume, and market saturation. In highly saturated markets, hierarchical precision matters more. It provides cleaner separation between expertise areas, positioning angles, and content relationships.
High-level topics are the primary knowledge categories the business operates within. Four to eight is the right scope for most businesses at early content maturity.
Subtopics add breadth within a domain without expanding into new domains prematurely.
Start with fewer topics and build genuine depth (see maturity levels) within them first. A business with strong coverage across a small number of subtopics compounds authority faster than one spread thinly across many. Hierarchy develops naturally as content matures. Imposing it before the content exists to populate it produces structure with nothing beneath it.
Topics do not change when retrieval signals change.
- Search behaviour shifts.
- Retrieval mechanisms evolve.
- The language people use to find information changes over time.
None of that affects the underlying knowledge domain. “Conflict resolution” (https://en.wikipedia.org/wiki/Conflict_resolution) is the same knowledge domain regardless of how people phrase their search, which platform they use to ask, or how AI systems have updated their retrieval models since the taxonomy was built.
This stability is deliberate and structural. Content built against a stable taxonomy builds authority in those domains. Content built against shifting retrieval signals requires constant rebuilding, .
When retrieval signals change and content performance shifts, the diagnostic question is not “what are people searching for now?” It is “is our existing taxonomy coverage at sufficient depth and maturity?”
How the Taxonomy Is Generated
The generation process asks: what are the distinct knowledge domains this business genuinely has standing to author within? Not what would attract traffic. Or what are competitors are covering.
You need to ask: What does this business actually know, and at what depth?
The result is a taxonomy that reflects real expertise, which is what makes it defensible to buyers, legible to search systems, and citable by AI retrieval mechanisms.
In Practice: What a Taxonomy Looks Like
The One Team QLD strategy illustrates a well-formed taxonomy at early implementation stage. The business operates across six high-level topics, Relationships, Mental Health and Wellbeing, Personal Growth, Leadership, Therapeutic Approaches, and Inclusive Practice, with 23 subtopics distributed across them.
Each high-level topic describes a genuine knowledge domain the practice has standing within. Each subtopic is discrete enough to warrant separate treatment and broad enough to support multiple content angles. The taxonomy was derived entirely from the practice’s expertise, credentials, and service model, not from retrieval data.
On working with AI systems to develop your taxonomy:
The distinction between a knowledge domain and a search term matters in practice, not just in theory. When developing or refining a topic taxonomy with an AI system, the framing of the prompt produces structurally different output. Asking “what topics should I cover?” tends to return retrieval-oriented suggestions. Asking “what knowledge domains does this business genuinely own?” returns taxonomy-oriented output. The difference in downstream content architecture is significant.
See also: Topical Authority, What The Library Knew Before Google Did for the conceptual background on why this distinction matters.
Commonly Conflated Concepts
Several adjacent concepts are regularly treated as interchangeable with a topic. They are not and each serves a different function.
A search term A search term is the string of words a person enters into a retrieval system, a search engine, an AI chat interface, a voice query.
It is behavioural and linguistic: it reflects how someone happens to phrase a question at a particular moment. The same underlying information need produces different search terms across different people, different platforms, and different points in time. A search term is an expression of intent.
A topic is the knowledge domain that intent points toward. When content strategy is built around search terms, it reacts to behaviour. When it is built around topics, it constructs knowledge. The former requires constant recalibration. The latter builds topical coverage and authority.
An article title An article title (or an article idea, content outline etc) is the specific treatment of a topic at a particular moment, one angle, one audience, one maturity level, one cluster framing.
A single topic can produce dozens of articles across its lifetime as coverage deepens and the cluster framing matures. The topic “Conflict Resolution” in a couples counselling practice might produce a professional-level piece on why arguments recur, an expert piece on applying the Gottman Four Horsemen, and thought leadership articles drawing on anecdotal evidence to show the structural patterns beneath recurring conflict. Three articles. One topic.
Treating article titles as topics produces a structure with no stable organising principle. Every entry could plausibly belong to multiple groups. The architecture requires constant human judgement. Nothing in the structure itself resolves the ambiguity. The categorisations are always arguable.
A content idea A content idea is an observation about what might be interesting or useful to write about. Content ideas are generative and abundant, they emerge from client conversations, industry reading, social observation, and competitive analysis. They are an input to the content planning process, not a structural unit.
A content idea earns a place in the content plan when it can be mapped to a valid taxonomy topic. If it cannot, that is a signal either that the taxonomy needs extending or that the idea does not serve the Known-For Position.
A subject In the library sense, a subject is the specific thing a particular work discusses, the concrete focus of a single text. A book about the 1969 moon landing has the subject “Apollo 11.” Its topic classification is “Space Exploration” or “Aeronautics.”
The subject is particular and specific. The topic is structural and repeatable.
Content planning operates at topic level. Individual pieces of content operate at subject level. Conflating the two is what produces taxonomies that are actually just lists of article ideas with no structural logic beneath them.
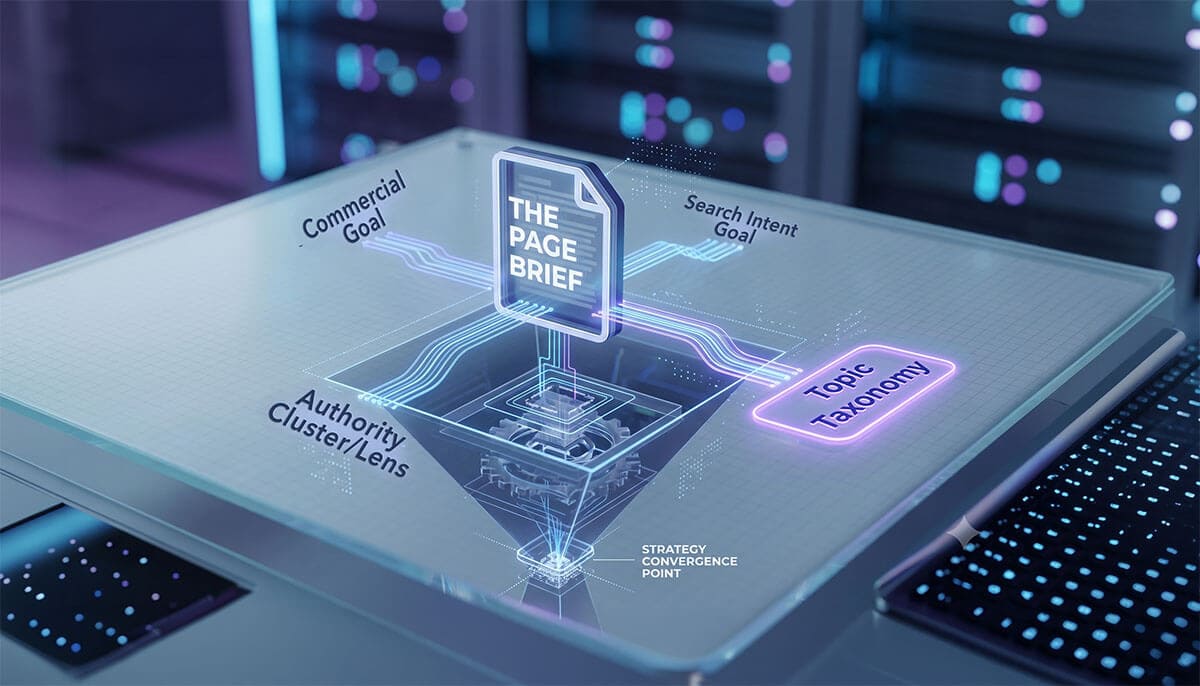
Relationship to Other Framework Components
The Topic Taxonomy exists independently of Authority Clusters.
Topics are not children of clusters, and clusters do not contain topics.
Both are assigned separately at the page level, the relationship between a topic and a cluster exists only when and because the a piece of content carries both assignments simultaneously.
This independence is intentional. The same topic can be addressed through different cluster lenses in different pieces of content. “Conflict Resolution” approached through a “Relationship Reconnection” lens produces different content than “Conflict Resolution” approached through an “Integrated Wellness Approach” lens, same knowledge domain, different positioning angle, different audience framing.
The taxonomy is also independent of the maturity level assigned to any individual piece of content. A topic can be covered at Entry maturity in one piece and at Expert maturity in another. The topic does not change. The depth of ideas, opinions and unique insights does.
Topics connect to Commercial Pathways at the content writing stage, when each piece of content is mapped to the service endpoint it supports. That mapping happens at content level, not at taxonomy level.
Topics intersect with a third layer not yet fully documented in this framework: entity relationships.
Entities: named people, tools, methodologies, organisations, certifications, locations. They are the specific things that populate a knowledge domain and make it verifiable to machine systems.
The relationship between topics and entities is architecturally distinct from the topic and authority cluster relationship and is documented separately in the Schema and Entity Architecture section.
Entity tracking within SCOS is currently in early development.